.NET and Node.JS - Performance Comparison (Updated)
Update (3/31/2013 - 11:41 PM PST):
This article has been updated! As most readers have commented the node.js async package is not asynchronous, which is what the original article was based on. I made an assumption I should not have. I have since rerun the tests taking this into account, as well as some of the changes recommended by Guillaume Lecomte. I have decided to update this existing post so that there’s no confusion in the future with the data. Thank you everyone for all the comments, posts and keeping me sane.
Update (3/29/2013 - 3:43 PM PST):
There’s been a lot of valid comments around the use of the async NPM package for node.js which are valid. I will take them into account and re-run these tests. If you talk to any silicon valley startup today chances are you will hear about node.js. One of the key reasons most argue is that node.js is fast, scalable because of forced non-blocking IO, and it’s efficient use of a single threaded model. I personally love JavaScript, so being able to use JavaScript on the server side seemed like a key gain. But I was never really sold into the notion that node.js is supremely fast because there aren’t any context switches and thread synchronizations. We all know these practices should be avoided at all costs in any multi-threaded program, but to give it all away seemed like an extreme. But if that meant consistently higher performance, then sure, that would make sense. So I wanted to test this theory. I wanted to find out exactly how fast node.js was compared to .NET - as empirically as possible. So I wanted to come up with a problem that involved IO (ideally not involving a database), and some computation. And I wanted to do this under load, so that I could see how each system behaves under pressure. I came up with the following problem: I have approximately 200 files, each containing somewhere between 10 to 30 thousand random decimals. Each request to the server would contain a number such as: /1 or /120, the service would then open the corresponding file, read the contents, and sort them in memory and output the median value. That’s it. Our goal is to reach a maximum of 200 simultaneous requests, so the idea is that each request would have a corresponding file without ever overlapping. I also wanted to align the two platforms (.NET and Node.js). For instance, I didn’t want to host the .NET service on IIS because it seemed unfair to pay the cost of all the things IIS comes with (caching, routing, performance counters), only to never use them. I also avoided the entire ASP.NET pipeline, including MVC for the same reasons, they all come with features, which we don’t care about in this case. Okay, so both .NET and Node.JS will create a basic HTTP listener. What about client? The plan here is to create a simple .NET console app that drives load to the service. While the client is written in .NET, the key point here is that we test both .NET and Node.JS services using the same client. So at a minimum how the client is written is a negligible problem. Before we delve into the details, let’s look the graph that shows us the results: 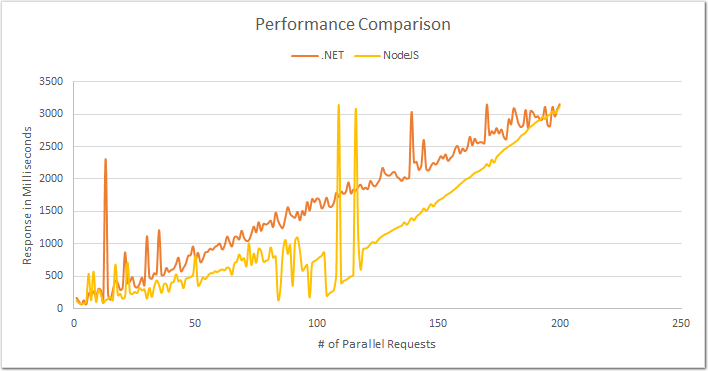
On an average Node.js wins hands down. Even though there are few spikes that could be attributed to various disk related anomalies, as some of the readers have eluded to. I also want to clarify that if you look at the graph carefully you start to see that the two lines start to intersect towards the end of the test run, while that might start to give you the impression that overtime the performance for .NET and node.js converge the reality is .NET starts to suffer even more over time. Let’s look at each aspect of this test more carefully. We’ll start with the client, the client uses a HttpClient to drive requests to the service. The response times are maintained on the client side so that there aren’t any drastic implementation difference on the service that could impact our numbers. Notice that I avoided doing any Console.Write (which blocks) until the very end.
public void Start()
{
Task[] tasks = new Task[this.tasks];
for (int i = 0; i < this.tasks; ++i)
{
tasks[i] = this.Perform(i);
}
Task.WaitAll(tasks);
result.ToList().ForEach(Console.WriteLine);
}
public async Task Perform(int state)
{
string url = String.Format("{0}{1}", this.baseUrl, state.ToString().PadLeft(3, '0'));
var client = new HttpClient();
Stopwatch timer = new Stopwatch();
timer.Start();
string result = await client.GetStringAsync(url);
timer.Stop();
this.result.Enqueue(String.Format("{0,4}\t{1,5}\t{2}", url, timer.ElapsedMilliseconds, result));
}
With that client, we can start looking at the service. First we’ll start with the node.js implementation. One of the beauties of node.js is it’s succinct syntax. With less than 40 lines of code we are able to fork processes based on the number of CPU cores and share the CPU-bound tasks amongst them.
var http = require('http');
var fs = require('fs');
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
}
else {
http.createServer(function(request, response) {
var file = parseInt(request.url.substring(1));
file = file % 200;
file = String("000" + file).slice(-3);
// read the file
fs.readFile('../data/input'+file+'.txt', 'ascii', function(err, data) {
if(err) {
response.writeHead(400, {'Content-Type':'text/plain'});
response.end();
}
else {
var results = data.toString().split("\r\n");
results.sort();
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('input'+file+'.txt\t' + results[(parseInt(results.length/2))]);
}
});
}).listen(8080, '127.0.0.1');
}
console.log('Server running at http://127.0.0.1:8080/')
And lastly, let’s look at the .NET service implementation. Needless to say we are using .NET 4.5, with all the glories of async/await. As I mentioned earlier, I wanted to compare purely .NET without IIS or ASP.NET, so I started off with a simple HTTP listener:
public async Task Start()
{
while (true)
{
var context = await this.listener.GetContextAsync();
this.ProcessRequest(context);
}
}
With that I am able to start processing each request, as requests come in I read the file stream asynchronously so I am not blocking my Threadpool thread, and perform the in-memory sort which is a simple Task that wraps the Array.Sort. With .NET I could have severely improved performance in this area by using parallel sorting algorithms which come right of the parallel extensions, but I choose not to because that really isn’t the point of this test.
private async void ProcessRequest(HttpListenerContext context)
{
try
{
var filename = this.GetFileFromUrl(context.Request.Url.PathAndQuery.Substring(1));
string rawData = string.Empty;
using (StreamReader reader = new StreamReader(Path.Combine(dataDirectory, filename)))
{
rawData = await reader.ReadToEndAsync();
}
var sorted = await this.SortAsync(context, rawData);
var response = encoding.GetBytes(String.Format("{0}\t{1}", filename, sorted[sorted.Length / 2]));
await context.Response.OutputStream.WriteAsync(response, 0, response.Length);
context.Response.StatusCode = (int)HttpStatusCode.OK;
}
catch(Exception e)
{
context.Response.StatusCode = (int)HttpStatusCode.BadRequest;
Console.WriteLine(e.Message);
}
finally
{
context.Response.Close();
}
}
private async Task<string[]> SortAsync(HttpListenerContext context, string rawData)
{
return await Task.Factory.StartNew(() =>
{
var array = rawData.Split(new string[] { "\r\n" }, StringSplitOptions.RemoveEmptyEntries);
Array.Sort(array);
return array;
});
}
You can download the entire source code, this zip file includes both client, and service sources for both .NET and node.js. It also includes a tool to generate the random number files, so that you can run the tests on your local machine. You will also find the raw numbers in the zip file. I hope this was useful to you all as you’re deciding to choose the next framework to build your services on. For most startups the key pivot point is performance, scalability over anything else and node.js clearly shines as we’ve shown today. Also, please remember some of the comments below are based on the original article which was using the async NPM package. This article has since been updated with the corrected information.
Comments
Came here from LinkedIn or X? Join the conversation below — all discussion lives here.